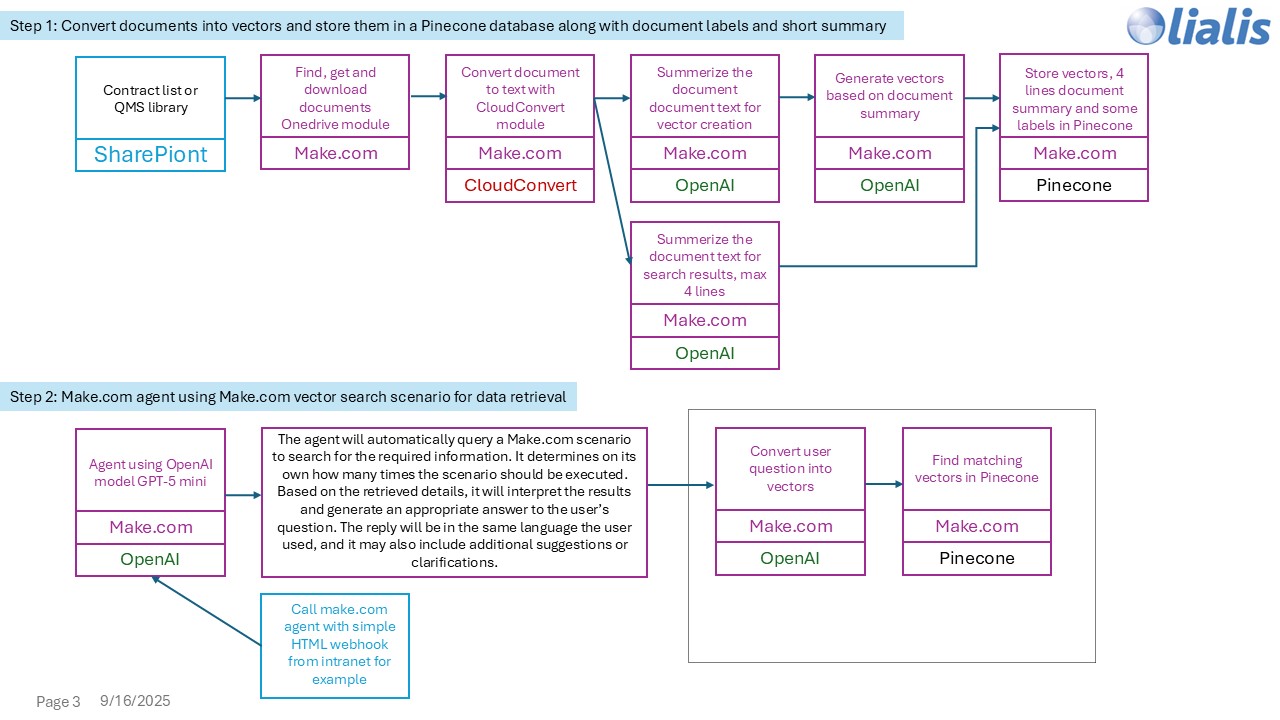
AI-Powered contractanalyse in Shareflex
Shareflex Contract is een uitstekend systeem om zowel inkomende als uitgaande contracten te beheren.
In deze post laten we u zien hoe onze AI-gestuurde contractoplossing complexe vragen over uw contracten kan beantwoorden.
Voorbeelden van vragen die het systeem moet kunnen beantwoorden
- Identificeer contracten met boetebepalingen en leg de kosten uit in het slechtste geval.
- Markeer contracten die schadelijk kunnen zijn voor het bedrijf en leg de risico’s uit.
- Identificeer bestaande NDA-overeenkomsten en geef een samenvatting van hun inhoud.
Het handmatig analyseren van dergelijke vragen kan tijdrovend zijn voor een contractmedewerker.
Probeer het zelf uit
In de onderstaande chatbot kun je de AI elke vraag stellen over de Shareflex contractdocumenten die zijn opgeslagen in de Lialis sandboxomgeving. De omgeving bevat ongeveer 20 contractdocumenten met zorgvuldig opgestelde NDA’s en voorbeeldclausules, zodat de resultaten zinvol zijn. Je kunt gerust vervolgvragen stellen, net zoals in ChatGPT. Veel succes!
Lialis AI (Shareflex Contract)
Hoe het is gebouwd